`x = Pépin, y = x` I'm Pépin too, says y
- 6 minutes read - 1091 wordsPass-by-Value or Reference: the Great Debate
Background on Heap and Stack
The stack referred to when talking about memory is the same as the run-time call stack. It is
composed of stack frames and stores things. It controls the function calls and program execution by
storing in its frames the function parameters, the return address, local variables - among other things.
The stack has a fixed-size so in some cases, for instance deep recursion, it can run out of memory.
Remember this one time you forgot a stopping condition in your code and got a StackOverflowError or
RecursionError: that’s the call stack telling you it’s full.
Stack frames only exist during the execution of a function. This means everything stored in it becomes
unavailable after the function has returned. This makes the allocation and de-allocation of memory
automatic, which helps prevent memory leaks.
To dig a little deeper, the stack is managed using a stack pointer. Allocating memory means moving the pointer “down” as the stack grows while de-allocating memory means moving the pointer up to reclaim the space. Offsetting the stack pointer implicitly tells us a stack frame has a known-size at compile time and that frames are stored in contiguous blocks of memory. As a result, only objects of fixed-size known at compile time can be stored in the stack.
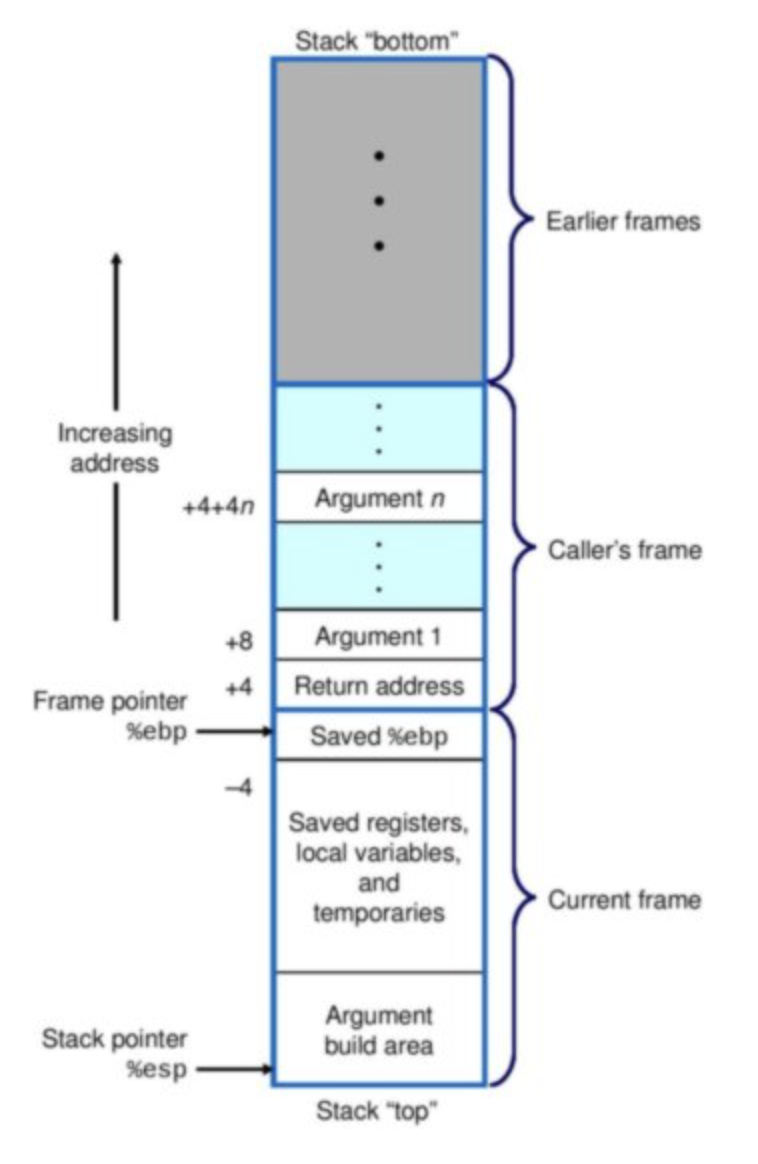
On the other hand, the heap memory is a dynamic memory storage. The heap differs from the stack because it can be resized. It is used for objects which scope are beyond a function; in fact, the objects stored there remain in the heap even after a function returns. The heap memory is essential for larger, dynamic data-structures whose size isn’t known at compile time. Storage in the heap is non-contiguous and its management is not automatic which can cause memory fragmentation and leaks. This also creates some overhead when it comes to access data in the heap. Hence, it requires handling, either manually by the programmers (C) or by other mechanisms, namely garbage-collectors (Java, Python).
In other words, with the heap we trade speed for flexibility.
Note each thread has its own stack while the heap space is shared between threads.
Slight differences depending on the languages
For both, frames and object references belong in the stack. In Python, object references are stored on the stack, while most actual objects (like lists and dictionaries) live on the heap. Some small, immutable objects may be stored in specialized areas for optimization.
However, Java also uses the stack to store primitives
declared in the local scope. Objects declared using the new keyword are stored in the heap.
Back to the “pass-by” debate
Referring to “pass-by x”, whatever the method described, aims to describe how are the function arguments passed from one stack frame to the next one. Does the next stack receive the parameters value as copies or do they directly receive a pointer to the object memory address?
It becomes important to consider when changes are made to a value: will this change be visible outside of the function scope or not? Simply put, when a copy of a value is passed to a stack frame, the changes made to it do not affect the original value - which is technically out of the function’s scope.
However, when a reference to the object is passed, modifications affect the original object.
Java à l’oeuvre
The short answer for Java: it is always pass-by-value. This should make it simple, right?
The caveat is that sometimes … those values are erm … values of … references. Let’s clarify.
Primitives are passed-by-value of their value aka copies. Any object (!= primitive) type in Java is also passed-by-value but of its reference because when dealing with variables holding objects, we are really dealing with “references”. Since the function only holds a copy of the reference-value, it is not possible to change what the caller’s reference points to.
In other words, operations on mutable objects do reflect on the original object.
However, re-assignment
of the variable to something else does not impact the original object nor the original object
reference.
Even in the case of a value-of-reference, we’re simply pointing to a different object in memory.
This is what we witness in the below example when setting the name to Daisy with a simple
assignment.= in the changeNameAndAgeIncorrect function.
public class Main {
public static void main(String[] args) {
Pet dog = new Dog();
dog.setName("Pepin");
dog.setAge(3);
changeNameAndAge(dog.getAge(), dog.getName());
System.out.println("Dog's Name: " + dog.getName());
System.out.println("Dog's Age: " + dog.getAge());
changeNameAndAge(dog);
System.out.println("Dog's Name: " + dog.getName());
System.out.println("Dog's Age: " + dog.getAge());
}
public static void changeNameAndAgeIncorrect(int age, String name) {
age = 10;
name = "Daisy";
}
public static void changeNameAndAge(Pet dog) {
dog.setAge(10);
dog.setName("Daisy");
}
}
Dog's Name: Pepin
Dog's Age: 3
Dog's Name: Daisy
Dog's Age: 10
And Python?
While Python is often called ‘pass-by-assignment,’ it can be thought of as pass-by-value of the reference—similar to Java. The key difference lies in Python’s name-binding model, which allows functions to reassign local names without affecting the caller.
In Python, all values are objects—even numbers and strings. Being dynamically typed, names in Python have no fixed type. Any name can refer to any value at any time.
When you pass an argument to a function, Python assigns a new local name to the same object. This means that mutable objects (e.g., lists or dictionaries) can be modified within a function, but reassigning the parameter to a new object won’t affect the original reference outside the function.
x = 23
y = x
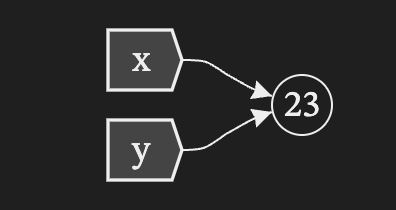
Here, both x and y point to the same object. Changing x won’t affect y, as Python simply binds names to objects. It is the same for an assignment within a function, the variable name points to a new object.
This behavior is shown in the following example, where one function modifies the original
list, while the other append_to_list_incorrect reassigns a new list—without
affecting the caller’s list.
def append_to_list(a_list, val):
"""Put `val` on the end of `a_list` twice."""
a_list.append(val)
a_list.append(val)
def append_to_list_incorrect(a_list, val):
"""Put `val` on the end of `a_list` twice."""
a_list = a_list + [val, val]
nums = [1, 2, 3]
append_to_list_incorrect(nums, 4)
print(nums) # [1, 2, 3]
append_to_list(nums, 4)
print(nums) # [1, 2, 3, 4, 4]
In short:
- Mutating an object affects the caller.
- Reassigning a name does not.
- Practically, for a programmer who cares about objects mutation, there’s no real difference between the two languages.
References
- Ned Batcheler
- Real Python
- Computer Systems: A Programmer’s Perspective, Randal E. Bryant and David R. O’Hallaron,