No Huff and Puff—Just Compress!
- 5 minutes read - 889 wordsThe Huffman’s Algorithm
The Huffman’s algorithm was born in 1952 as a way to perform a lossless compression on data files. Its efficiency comes from the frequency analysis of characters present in the text to encode: shorter codes are used to encode more frequent characters while longer codes are used to encore less frequent ones.
It constitutes the foundation of modern text compression.
You can read more on variable-length encoding and tree representations under the Design tag on this blog.
Given the sequence 001, how do we know we should decode it as 0 & 01 and not 001?
Huffman’s codes for characters are never the prefix code for
another character. Thanks to this, there is no ambiguity when decoding the text.
In this example, the algorithm would not output 0 & 01 codes together.
How it works
The algorithm is based on frequency analysis of characters in the text to encode. The least two frequent characters are then put into a binary tree, which root node is the result of their combined frequency. This operation is repeated until there is only one node left.
The code for a given character is then the path followed along the binary tree to
reach this character; by convention left nodes carry the 0 direction while
right nodes carry 1.
To aid with visual representation, the below is an example of such tree.
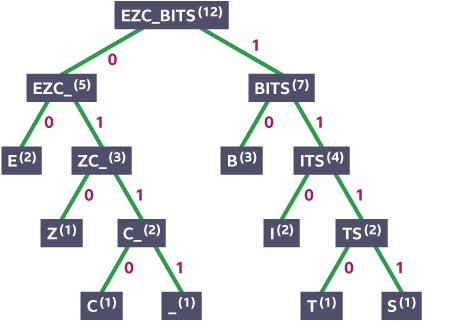
Practical Example
To represent the Huffman’s code, we first need to define a Huffman’s node. Since we
will be processing pairs of least frequent nodes, a min heap is used. The Huffman’s node
requires to implement the less than magic method __lt__.
Note we need to handle the case where two characters have the same frequency by comparing their symbol instead.
class Huffman_Node:
def __init__(self, freq, symbol, left=None, right=None):
self.freq = freq
self.symbol = symbol
self.right = right
self.left = left
self.dir = ''
def __lt__(self, other):
if self.freq == other.freq:
return self.symbol < other.symbol
return self.freq < other.freq
def __str__(self):
return f'Symbol: {self.symbol}, Freq: {self.freq}, Left: {self.left}, Right: {self.right}'
From there, the Huffman’s tree can be generated. Traversing the tree and building paths to the child nodes provides the codes given to each character of the text. Those paths are kept in encoding/decoding tables.
import heapq
from collections import Counter
class Huffman_Tree:
def __init__(self):
self.root = None
self.encoding_table = {}
self.decoding_table = {}
def _build_encoding_table(self, text):
frequencies = Counter(text)
self._get_huffman_coding(frequencies)
def traverse(node, path=""):
if not node:
return
if not node.left and not node.right:
self.encoding_table[node.symbol] = path
self.decoding_table[path] = node.symbol
return
if node.left:
traverse(node.left, path + str(node.left.dir))
if node.right:
traverse(node.right, path + str(node.right.dir))
return traverse(self.root)
def _get_huffman_coding(self, frequencies):
nodes = []
for char, freq in frequencies.items():
heapq.heappush(nodes, Huffman_Node(freq, char))
while len(nodes) > 1:
left = heapq.heappop(nodes)
right = heapq.heappop(nodes)
# assign directional value, convention is 0 left, 1 right
left.dir = 0
right.dir = 1
combined_node = Huffman_Node(left.freq + right.freq, left.symbol + right.symbol, left, right)
heapq.heappush(nodes, combined_node)
#print([str(node) for node in nodes])
self.root = nodes[0]
The encode method builds the encoding table and processes each character one by one, following
the encoding table.
The decode method decodes the first sequence of bits found in the decoding table.
This is possible thanks to the property of the Huffman’s algorithm not to encode
a character with another’s prefix. This provides the guarantee that the first known
found sequence is the correct one.
This is done simply using a two pointers method.
class Huffman_Tree:
def encode(self, text):
self._build_encoding_table(text)
encoded_text = ''
for c in text:
encoded_text += self.encoding_table[c]
return encoded_text
def decode(self, text):
if not self.decoding_table:
print('Decoding table not built! Unable to proceed')
return ''
# prefixes of the table are guaranteed to not be shared with other
decoded_text = ''
l, r = 0, 0
while r < len(text):
curr_bits = text[l:r+1]
if curr_bits in self.decoding_table:
decoded_text += self.decoding_table[curr_bits]
l = r + 1
r += 1
return decoded_text
Fancy a run?
The below code encodes and decodes the test string “leane.dev is my bedtime read; counting bits guaranteed”.
if __name__ == '__main__':
tree = Huffman_Tree()
### My Example ###
example_str = "leane.dev is my bedtime read; counting bits guaranteed"
encoded_example = tree.encode(example_str)
print(f'The encoded example is: \n{encoded_example} \n with length {len(encoded_example)} \n while original length'
f' was {len(example_str)}\n')
print(f'Encoding table is: \n {tree.encoding_table}')
print(f'Decoding table is: \n {tree.decoding_table}')
decoded_str = tree.decode(encoded_example)
print(f'Decoded string is: {decoded_str}')
The encoded example is:
10001110101111110101011010100110111110101011010000010110010110001010000101100100111011100110101011111101011110010110110101000101111000001111000111011110110000101000011010010000010110000001011111111011111100011011011001
with length 218
while original length was 54
Encoding table is:
{'s': '0000', 'u': '0001', 't': '001', ' ': '010', 'y': '01100', '.': '011010', ';': '011011', 'a': '0111', 'b': '10000', 'c': '100010', 'l': '100011', 'd': '1001', 'e': '101', 'g': '11000', 'm': '11001', 'i': '1101', 'n': '1110', 'o': '111100', 'v': '111101', 'r': '11111'}
Decoding table is:
{'0000': 's', '0001': 'u', '001': 't', '010': ' ', '01100': 'y', '011010': '.', '011011': ';', '0111': 'a', '10000': 'b', '100010': 'c', '100011': 'l', '1001': 'd', '101': 'e', '11000': 'g', '11001': 'm', '1101': 'i', '1110': 'n', '111100': 'o', '111101': 'v', '11111': 'r'}
Decoded string is: leane.dev is my bedtime read; counting bits guaranteed
Encoding this 54 characters example string would have required 432 bits or 54 bytes following the ASCII scheme.
Using the Huffman’s algorithm, we could do it with only 218 bits, representing a 50% compression.
Even assuming a 7 bits ASCII encoding, we reach a 43% compression!